؟Imbalanced Datasets كيف نتعامل مع
ما المشاكل الى تسبّبها وما حلولها؟
من المشاكل الى قابلتها في الكورسات إن الـdataset أحياناً بتكون خالية من العيوب الى ممكن نلاقيها في أرض الواقع، وفي مجال الـclassification، فيه فرصة كبيرة إننا نتعامل مع imbalanced datasets لإن الأكيد إن مش كل الـclasses بتحدث بنفس النسبة وبالتالي الغير طبيعي هو إن لما أجمع data أشوف كل الـclasses بنفس الrate ، لكن ليه الـimbalance ده ممكن يسبب مشكلة أصلا؟
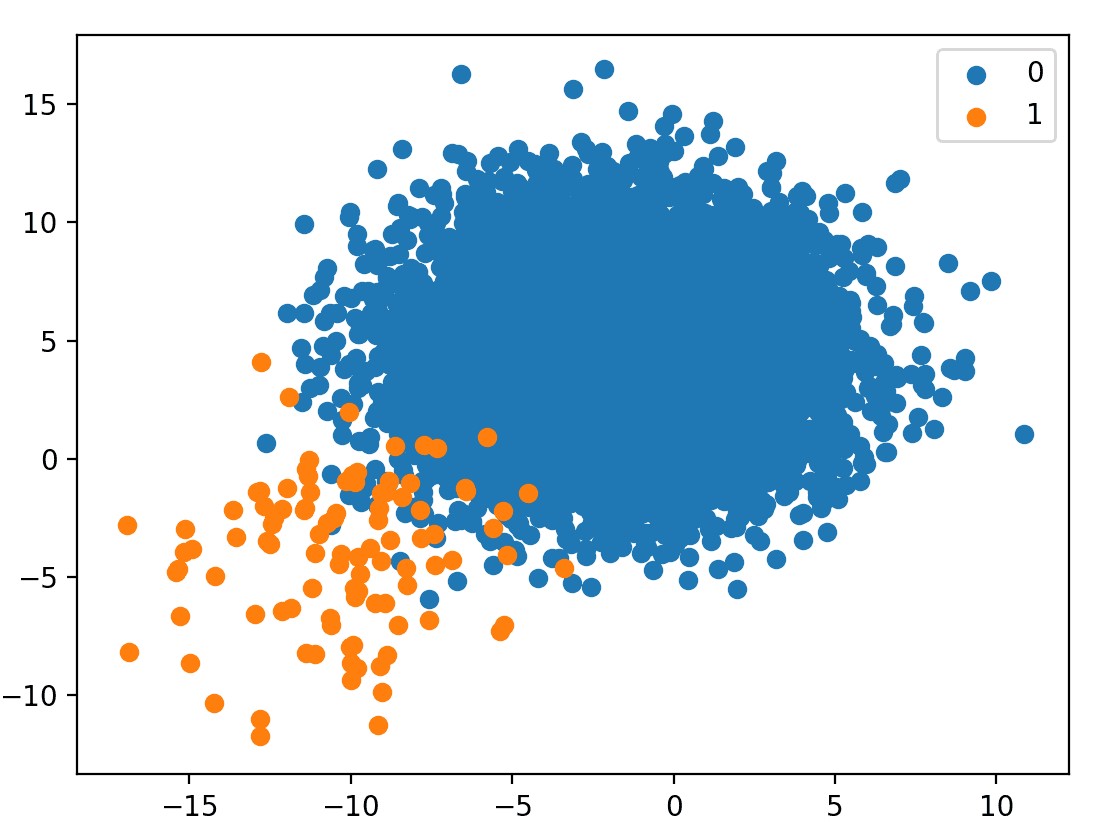
Fig 1: Example of an imbalanced dataset
نتيجة جيدة بالنسبة لأول تجربة صح؟
في البداية ممكن تتفق، لكن خلينا نلقي نظرة على الdata الأول: لما بصيت على الداتا لقيت إن فيه 100 ريكورد فقط من بين الـ10 آلاف عندهم الورم، والباقي نتايجهم سلبية ، بمعنى آخر: 99% من المرضى الموجودين في الداتا مفيش عندهم ورم.تخيل معايا بقى إن أنا عملت موديل بيفترض إن كل المرضى مفيش عندهم ورم، يعني بيتنبأ إن كل العينات سلبية، الموديل الساذج ده قدر يوصل لـ99% accuracy من غير ما يعمل حاجة! يبقى هنا الـaccuracy أصبحت معيار غير صحيح لنتايج الموديل بتاعي.
ليه مقدرش أعتمد على الـaccruacy في مشكلة زى دى؟
طب إيه الحل؟ إزاي أقدر احكم على مدى صحة توقعات الموديل في الحالة دى؟
في المشكلة الى عندي، تكلفة إن المريض يبقى عنده ورم وأنا اتنبأ إن معندوش كبيرة جداً: الورم ممكن يكلفه حياته، فبالتالي لازم أختار measure بيتأثر تحديداً بنسبة الـFalse negative وهو الـrecall، لو حسبت الـrecall للموديل البسيط الى عندي هيساوي 0% وهنا تكون النتيجة منطقية.بعد ما عرفت الـmeasure الى أقدر احكم بيه على نتايج الموديل، الخطوة التالية هي إننا نعمل موديل بيتعلم بكفاءة من الـimbalanced data وبيأدي بشكل جيد سواء على الـmajority class (الى بتمثّل غالبيّة الـdataset) أو الـminority class،
طب ليه الـimbalance ممكن يسببلي مشكلة هنا؟
في مرحلة الtraining، الموديل بيهدف إنه يوصل للـparameters الى الـcost عندها أقل ما يمكن، خلال المرحلة دى (ولإن الـmajority class تمثّل غالبية الصفوف في الداتا)، هتلاقي إن معظم الـupdates رايحة ناحية تحسين نتائج الموديل على الـmajority class ، لإن فرصة الـmissclassification فيها أعلى بكتير، وده معناه إنها بتساهم في الـcost بشكل اكبر بكتير من الـminority class، فبالتالي هينتج موديل عنده bias ناحية الـmajority class وبيأدي فيها بشكل أفضل بكتير من الـminority class.
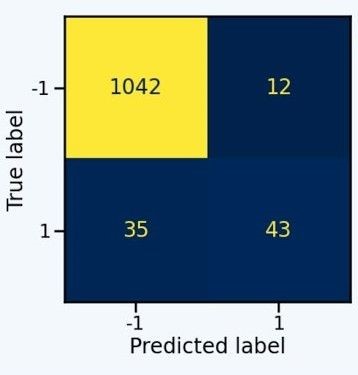
Fig 2: مثال على نتائج model بعد تدريبه على imbalanced dataset،
لاحظ نسبة الخطأ الكبيرة في الـminority class
Source: Click here
أحد الطرق الى ممكن تحل مشكلة الـclass imbalance هي إننا نخلق balance بنفسنا عن طريق الـdata resampling وده ممكن يتم بأكتر من طريقة:
الطريقة الأولى هي الـRandom Under-sampling: عندك class مسيطر عالداتا ؟ بسيطة: احذف صفوف منه عشوائياً لحد ما يتساوى بالـclass التاني.حل بسيط لكنه غير منطقي، الناس بتحاول تجمع أكبر قدر ممكن من الداتا، وانت رايح تحذفها؟! وهو فعلاً مش أفضل حل لإن حتى لو حلّيت مشكلة الـimbalance هتدخل في مشكلة تانية لإنك فقدت جزء كبير من الداتا ،وكمان ممكن الـsample الصغيرة الى حافظت عليها تكون biased ومش بتعبر عن الـmajority بشكل كويس ،وبالتالي مش هتلاقي نتيجة جيدة.
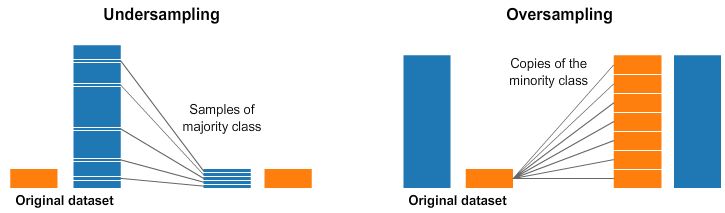
Fig 3: Random Undersampling Vs. Random Oversampling
الطريقة التانية هي الـRandom Over-sampling: بدل ما نحذف من الـmajority ، ممكن نكرر صفوف من الـminority بشكل عشوائي لحد ما تتساوى بالـmajority، وكده أكون تفاديت أي loss في الـdata وقدرت احل مشكلة الـimbalance.
لكن تظل عندي مشكلة تانية وهي إن الصفوف الى زودتها هى تكرار للصفوف الموجودة عندي في الداتا، وده معناه إنها redundant، ولذلك ممكن يحصل overfitting للموديل وميقدرش يوصل لـgeneralization جيد.
الطريقة التالتة هي الـSynthetic Minority Over-sampling: وهى بتحاول تحل مشكلة الـover-sampling عن طريق إنها تخلق صفوف جديدة من الـminority من الصفوف الموجودة فعلاً في الـdata. كده ضمنت حل الـimbalance وضفت data جديدة وحليت مشكلة الـredundant data.
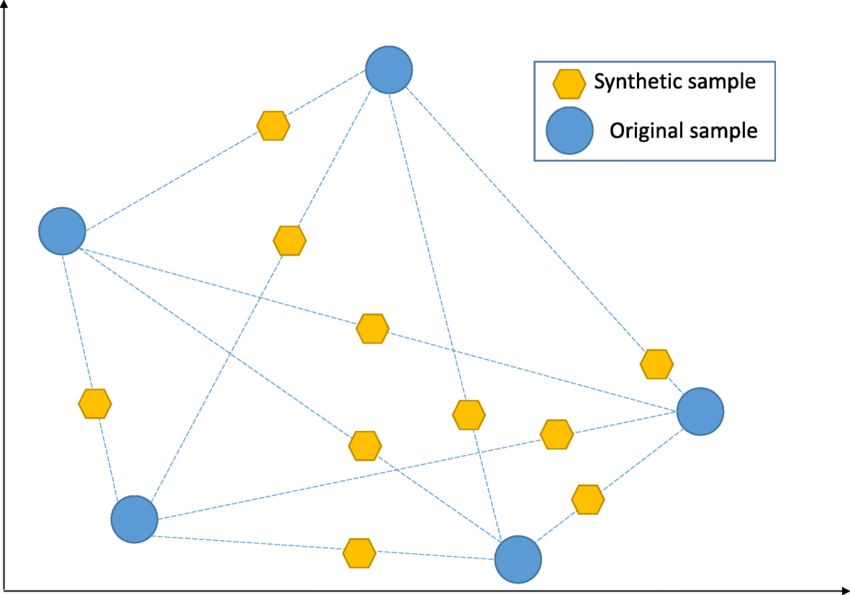
Fig 4: Synthetic Minority Over-sampling
طيب إزاي بنعمل data points جديدة من الداتا الأصلية؟
بتبدأ الأول بنقطة عشوائية من الـminority، وتحدد أقرب 5 نقط minority لها، بعد كده بتختار واحدة منهم وترسم خط بين النقطتين، النقطة الجديدة الى هضيفها هتكون أي نقطة عشوائية على الخط بين النقطتين دول. ممكن تتخيل الطريقة دى كإنك بتعمل interpolation بين النقط وتختار نقط عشوائياً على الخطوط دى.إيه أفضل طريقة من الـ3 طرق دول؟
اختيار الطريقة معتمد بشكل رئيسي على نوع الداتا، مفيش طريقة مضمون نجاحها بشكل كامل وممكن تحتاج تستخدم أكثر من طريقة مع بعض، وفي النهاية نتائج الموديل هي المعيار.حتى الآن تطرقنا لأكثر من طريقة لحل مشكلة الـimbalance عن طريق الـdata resampling، لكن فيه methods تانية لتقليل تأثير الـimbalance عن طريق الـmodels، هذكر أمثلة منها الآن
الطريقة الأولى هي الـCost-Sensitive training:
زى ما وضحنا سابقاً إن في مرحلة الـtraining بنلاقي إن الـparameters update دايماً بتكون في اتجاه تحسين نتايج الموديل على الـmajority class لإنها بتساهم بشكل أكبر في الـcost، طب إيه رأيك نرفع الـpenalty الخاصة بالـminority؟يعني إيه؟ ببساطة بدل ما أفترض إن كل الـclasses لهم نفس الوزن والتأثير على الـcost في الـtraining، هبدأ احط وزن أكبر للـminority class واحط وزن أقل للـmajority class.
كده في الـtraining لما يحصل error في الـminority هيكون له تأثير كبير على الـcost، وبالتالي قدرت أساوي تأثير الـmajority والـminority وقللت bias الموديل ناحية الـmajority
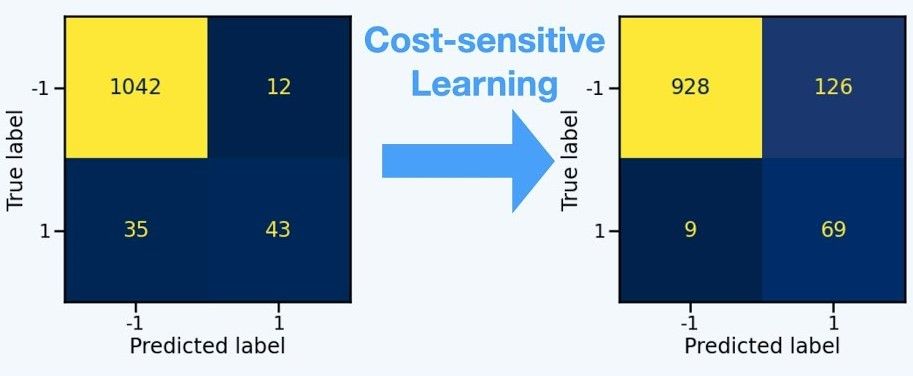
Fig 5: Effect of Cost Sensitive Training on model results.
Source: Click here
الطريقة التانية هى إننا نستخدم ensemble algorithm:
في الغالب أي ML model هنستخدمه لوحده مش هيأدي بشكل جيد في حالة الـimbalanced data، لذلك ممكن نلجأ لعمل ensemble من أكتر من model سواء عن طريق الـboosting (زى الـGradient boosted trees) أو الـbagging (زى الـRandom forest).الـensembles بتحقق نتايج أحسن بشكل عام، لكن ممكن نستغل الـbagging أكتر عن طريق إننا نحاكي الـunder-sampling داخل الـensembled models كالتالي:
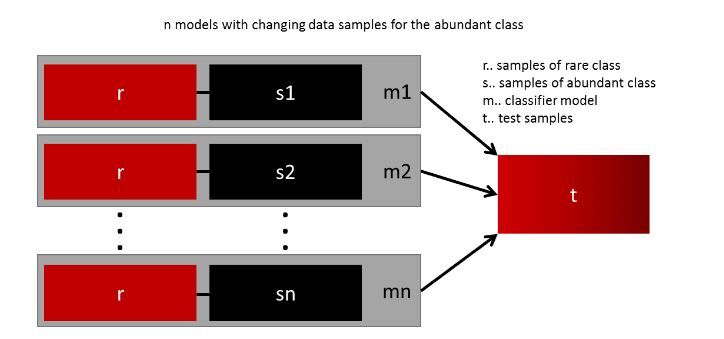
Fig 6: Model ensemble with data resampling.
Source: Click here
في الـbagging بنقسم الـdataset على كل موديل with replacement، ممكن نقسم احنا الداتا بحيث يكون جزء الـminority بالكامل موجود في كل موديل ونعمل sampling للـmajority ونوزعهم على كل موديل بالتساوي.
وكده يبقى كل موديل عنده عدد متساوي من الـmajority class والـminority class وفي نفس الوقت استخدمت كل الـdata ومخسرتش منها حاجة في الـunder-sampling.
- Machine Learning with Imbalanced Data - Part 2 (Cost-sensitive Learning)
- 7 Techniques to Handle Imbalanced Data
- Dealing with Imbalanced Data